Running Llama 3.1 70B on a Single Consumer-Grade GPU (RTX 4090 24GB) at 60 Tokens/s
Llama 3 is a series of large language models released by Meta AI in July 2024. It comes in different sizes, including 7B, 70B, and the largest, 400B parameters. The 70B model, with 70 billion parameters, requires 140 GB of VRAM for weights alone in the default FP16 precision (since each parameter takes 2 bytes). It is suppose to be on par with many leading LLMs and better than the famous GPT 3.5 which people came to know as 'ChatGPT'.
Setup
I was able to get a RTX 4090 machine with the following specs for cheap (0.3
USD / hour) on Vast AI.
These are the issues I’ve had with Vast AI if you want to go ahead:
- Download is often much slower than colab.
- Download/upload to your computer is cripplingly slow at least for me. 2GB
file took half an hour to download. Just somebody’s pc.
- They can view all your file/keys. It’s not encrypted afaik.
- Shut down vm may never get the GPU again when restarting. I don't know
what that means for accessing those files.
- CPU / RAM is shared.
+----------------------------------------------+ | Vast.ai Instance | +----------------------------------------------+ | GPU: 1 x RTX 4090 (24 GB VRAM, 82.2 TFLOPS) | | CPU: Xeon® E5-2695 v3 (16 cores) | | RAM: 64 GB | | Running PyTorch 2.2.0 + CUDA 12.1 | +----------------------------------------------+
Model Selection
Normally a model of this size would require a cluster of GPUs to run. Since our GPU only has 24 GB, it can't fit 140 GB model into memory. We need a trick called weight quantization to compress the weights in memory. As it is not a lossless process there is some impact to the model's overall quality. I am using 'Meta-Llama-3.1-70B-Instruct-IQ2_XS.gguf' from HuggingFace, which is a 2 bpw (2 bits per weight) version of the original model. This reduces the size by roughly 8-fold, from 140 GB down to 21.1 GB, fitting just under our GPU's limit.
Running the Model
Download the model from HuggingFace.
pip install -U "huggingface_hub[cli]" huggingface-cli download bartowski/Meta-Llama-3.1-70B-Instruct-GGUF --include "Meta-Llama-3.1-70B-Instruct-IQ2_XS.gguf" --local-dir ./
Normally, you'd run GGUF models with something like llama.cpp but I was unable to get it or koboldCpp to work with the GPU. Ollama is the one which worked for me.
Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
Although this step isn't listed in the Ollama instructions for using a GGUF model, you need to start the server first in a separate terminal.
ollama serve
Conitnue with the provided instructions to run the GGUF model. Create a file called Modelfile with the following contents which points to the file location.
FROM ./Meta-Llama-3.1-70B-Instruct-IQ2_XS.gguf
Create the Ollama model and then run it.
# Create the Ollama model ollama create example -f Modelfile # Run the model ollama run example
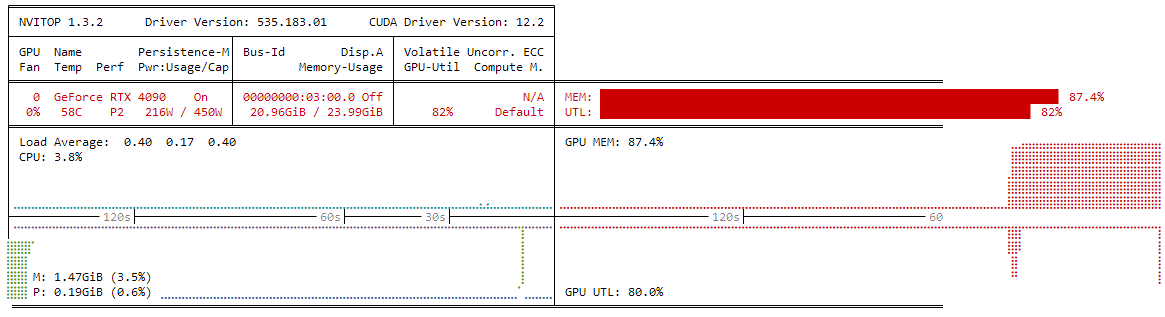
That's it. A chat prompt will open up. I was able to get decent speed of around 60 tokens / second. It consumed about 21GB of VRAM.