Which Countries Seed the Most? Mapping Seeder IPs on Movie Torrents.
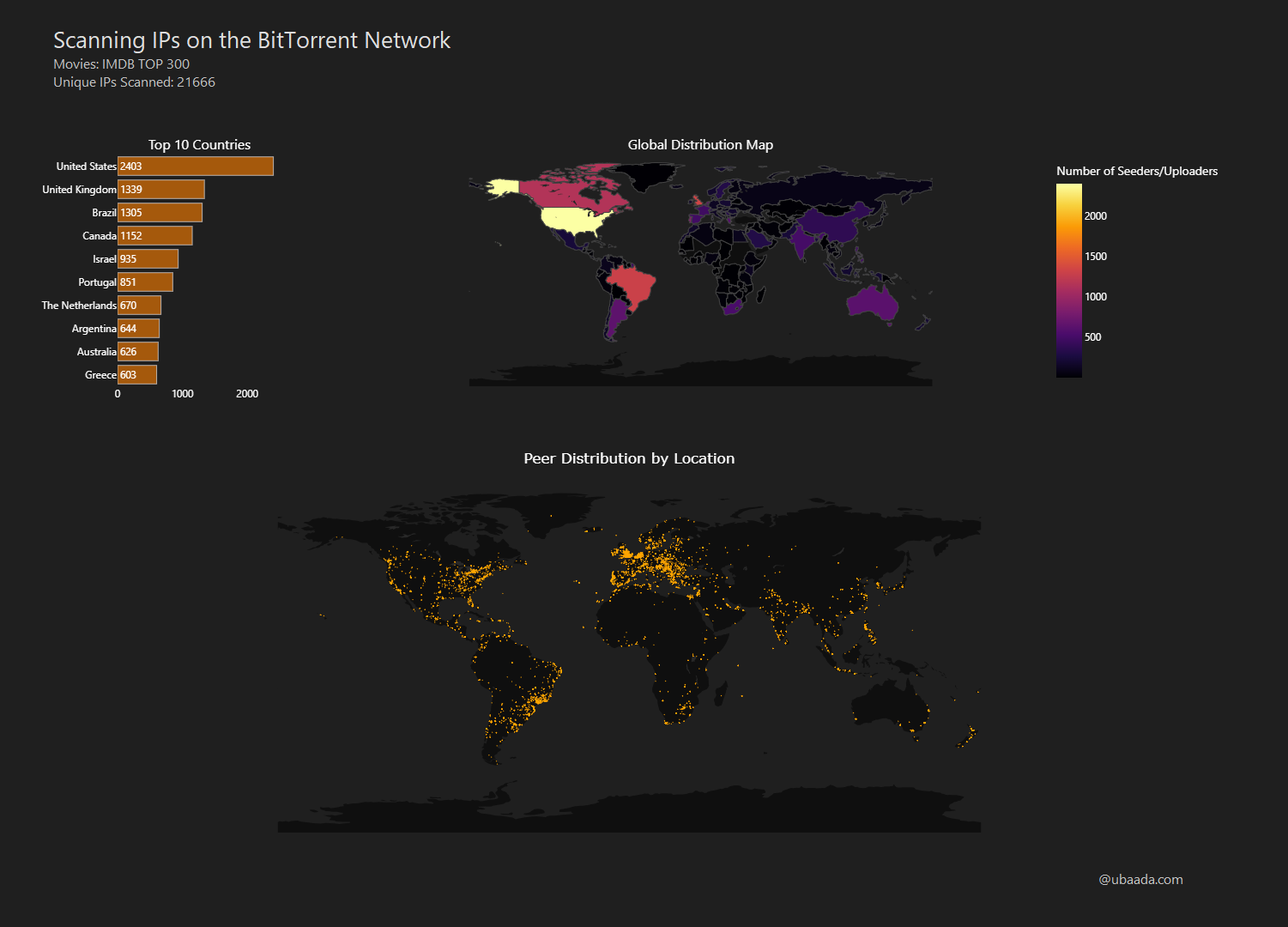
This visualization depicts BitTorrent seeder activity for the IMDB Top 300 movies, drawing from a scan of 21K unique IPs. A seeder here is defined as "a user on the BitTorrent who has a complete copy of a file and uploads it to other users on the BitTorrent network.'
- How does the BitTorrent protocol work
-
Procedure:
- Getting the movie list
- Getting the torrents
- Getting the IPs
- Translating IPs into location
- Drawing the plots
- Caveats
- Resources
How does the BitTorrent protocol work
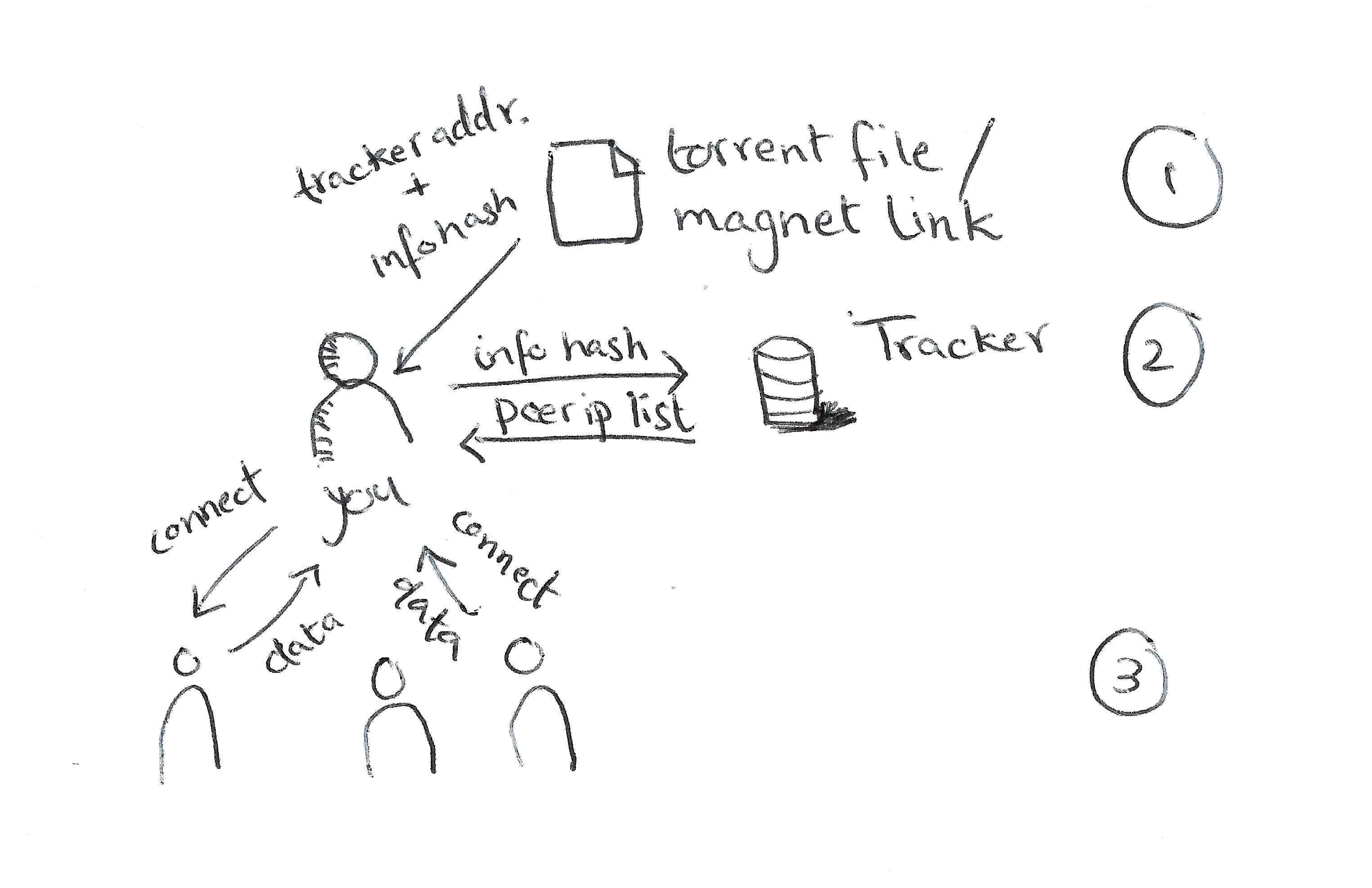
The torrent file-sharing system operates by initially requiring a user to obtain a torrent file or magnet link, which includes essential metadata needed to start the download, such as the tracker address and an info hash, a unique identifier for the file's content. The torrent client uses this information to connect to a tracker, a server that maintains a list of peers who are sharing the same file. This tracker provides the user with a list of IPs of the peers, enabling the client to connect directly to these peers. Trackers often return the list of IPs which are seeding with complete content i.e. after it has finished downloading not just during mutual exchange. So, the list will taken as seeders. Once connected, the client begins downloading pieces of the file from these peers while simultaneously uploading pieces to others.
The IP address of the participants is public so we can check who is downloading what. We can exploit this to check who is sharing pirated movies. For this, we need a list of movies, any torrent files related to them, and a list of IPs who are seeding the files related to the torrent to other users.
Procedure:
Getting the movie list
I used the IMDB top 250 list to scrape the movie titles. It, fortunately enough, loads way more movies and shows than 250. The results were exrtacted as JSON by running a simple javascript script in the chrome dev tools. I chose to ditch the shows later on because compatibility reasons later on because shows can have multiple episodes.
const listings = [...document.querySelectorAll('.sc-b189961a-0.iqHBGn')].map(container => {
const titleElement = container.querySelector('.ipc-title__text');
const episodeElement = container.querySelector('.sc-b189961a-5.hFrYod .ipc-title__text');
const result = {
movie_id: titleElement?.parentElement?.getAttribute('href').split('/')[2] || '',
name: titleElement ? titleElement.textContent.trim() : '',
type: episodeElement ? 'show' : 'movie',
episode_name_or_number: episodeElement ? episodeElement.textContent.trim() : ''
};
return result;
});
console.log(listings);
The results can be copied from chrome like so:
const jsonString = JSON.stringify(listings, null, 2);
copy(jsonString);
Ultimately, we are saving all our results from here onwards into a small sqlite database file. I am choosing sqlite here over other formats like json partially because of novelty but also because
- it has built in constraint checking mechanism like checking for uniqueness. Duplicate data is always a concern when web scrapping.
- It's easier to then analyse the data further using simple SQL queiries rather than messing around with nested 'for' loops.
Getting the torrents
How do you go from movie names to torrents? One way is web scrapping popular torrent sites. That is cumbersome. Fortunately, using Fiddler, I was able to intercept an application which uses an API to fetch info hashes of various torrents. It can intercept SSL traffic by inserting a fake root certificate on your behalf on to your system. There is a nice Computerphile video on how this works and it can go wrong. The API just takes IMDB ID of the movie and returns a list of info hashes of available torrents. However, it does not to return the trackers everytime which we need to connect to peers. For this, I used a list of popular top 20 trackers from GitHub for all our movie info hashes.
def get_torrent_info(imdb_id):
response = requests.get(f"https://torrentio.strem.fun/stream/series/{imdb_id}.json")
raw_log_file = "./pir-files/torrentio-logs.txt"
data = response.json()
# append the response to the log file
with open(raw_log_file, 'a') as file:
file.write(json.dumps(data) + '\n')
streams = data['streams']
torrent_info = []
for stream in streams:
try:
info_hash = stream['infoHash']
quality_type = stream['name'].split('\n')[1]
pattern = r"(.*) 👤 (\d+) 💾 (.*) ⚙️ (.*)"
match = re.match(pattern, stream['title'].replace('\n', ' '))
title, est_seeders, size, _ = match.groups()
# check if info_hash is already in the torrent_info list
if info_hash not in [info[0] for info in torrent_info]:
torrent_info.append((info_hash, title, int(est_seeders), size, quality_type))
except Exception as e:
pass
return torrent_infoGetting the IPs
We can use a popular library called libtorrent for python to interact with the BitTorrent network. However, to collect IPs it makes you download the files so you can note down the peers you were connected to along the way. We don't wanna do that. Instead the following python script makes simple UDP calls to trackers to collect the IPs of seeders. We don't connect to these IPs.
def parse_announce_response(announce_data):
try:
# Unpack the first part of the response
action, transaction_id, interval, leechers, seeders = struct.unpack("!IIIII", announce_data[:20])
# The rest of the data consists of peers
peer_data = announce_data[20:] # Get data beyond the first 20 bytes
num_peers = len(peer_data) // 6
# Loop through each peer and unpack their IP and port
peers = []
for i in range(num_peers):
offset = i * 6
ip, port = struct.unpack("!IH", peer_data[offset:offset + 6])
ip_address = socket.inet_ntoa(struct.pack("!I", ip))
peers.append((ip_address, port))
return {
'action': action,
'transaction_id': transaction_id,
'interval': interval,
'leechers': leechers,
'seeders': seeders,
'peers': peers
}
except struct.error as e:
print(f"Error parsing response: {e}")
return None
except Exception as e:
print(f"An unexpected error occurred: {e}")
return None
def get_peers(info_hash, tracker):
try:
# Step 1: Create a UDP socket
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
sock.settimeout(8)
# Step 2: Send Connect Request
transaction_id = random.randint(0, 65535)
connect_request = struct.pack("!QII", 0x41727101980, 0, transaction_id)
sock.sendto(connect_request, tracker)
# Step 3: Receive Connect Response
data, _ = sock.recvfrom(2048)
action, transaction_id, connection_id = struct.unpack("!IIQ", data[:16])
# Step 4: Send Announce Request
if action == 0 and transaction_id == transaction_id:
info_hash = bytes.fromhex(info_hash)
peer_id = b'-UT2300-000000000000' # 20-byte peer_id
downloaded = 0
left = 0
uploaded = 0
event = 0
ip = 0
key = 0
num_want = 200
port = 6881
announce_request = struct.pack("!QII20s20sQQQIIIIH", connection_id, 1, transaction_id, info_hash, peer_id, downloaded, left, uploaded, event, ip, key, num_want, port)
sock.sendto(announce_request, tracker)
# Step 5: Receive Announce Response
announce_data, _ = sock.recvfrom(2048)
# Parse the response
return parse_announce_response(announce_data)['peers']
except Exception as e:
raise e
finally:
# Close the socket
sock.close()
return NoneTranslating IPs into location
IPs are not location. To convert them into locations we need a map that tracks which IP belongs to which area. I am using GeoIP2, which provides a database that can be used to convert IP addresses into geographic locations. This database contains mappings of IP address ranges to location data such as country, city, and coordinates, enabling users to determine the location associated with an IP address by querying the GeoIP2 database. Putting it all together:
# load popular trackers from common-trackers.txt file
with open('./pir-files/common-trackers.txt', 'r') as file:
trackers = file.read().splitlines()
# parse the trackers into a list of tuples
trackers = [parse_tracker_string(tracker) for tracker in trackers]
print(f"Loaded {len(trackers)} trackers from file.")
# split the 20 trackers into 4 groups of 5 trackers each
# to avoid rate limiting and to distribute the load
tracker_groups = [trackers[i:i+5] for i in range(0, len(trackers), 5)]
# open connection to the database
conn = sqlite3.connect('./pir-files/tor-records.db')
cursor = conn.cursor()
# for each imdb_id, get the info_hash with the highest seeders
cursor.execute("SELECT imdb_id FROM movie")
torrents = cursor.fetchall()
# get the imdb_id+info_hash pairs with the highest seeders
max_seed_torrents = []
for imdb_id in torrents:
cursor.execute("SELECT info_hash, MAX(est_seeders) FROM torrent WHERE imdb_id=?", (imdb_id[0],))
if (result := cursor.fetchone()) != (None, None):
max_seed_torrents.append((imdb_id[0], result[0]))
print(f"Total torrents with max seeders: {len(max_seed_torrents)}")
# get the peers for each torrent
t = 0
from tqdm.auto import tqdm
movie_counter = tqdm(max_seed_torrents, leave=False)
for imdb_id, info_hash in movie_counter:
# check if the torrent has already been processed in the ip_rec table
cursor.execute("SELECT info_hash FROM ip_rec WHERE info_hash=?", (info_hash,))
if cursor.fetchone() is not None:
continue
uniq_ips = set()
t = (t + 1) % 4
movie_counter.set_postfix({"Tracker Group": t})
for tracker in tqdm(tracker_groups[t], leave=False):
try:
peers = get_peers(info_hash, tracker)
if peers:
for ip, _ in peers:
uniq_ips.add(ip)
movie_counter.set_postfix({"Uniq. IPs": len(uniq_ips)})
except Exception as e:
pass
# convert ip to location data and insert into the ip_rec table
for ip in uniq_ips:
try:
response = reader.city(ip)
cursor.execute("""
INSERT INTO ip_rec (info_hash, ip, iso_code, longitude, latitude, postal_code, city, country, continent)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
""", (info_hash, ip, response.country.iso_code, response.location.longitude, response.location.latitude, response.postal.code, response.city.name, response.country.name, response.continent.name))
conn.commit()
except Exception as e:
pass
Drawing the plots
Connect to the SQLite database to retrieve the count of seeders/uploaders by country, then create a world map colored by the number of seeders. I am using Plotly library here.
import plotly.graph_objects as go
import pandas as pd
import sqlite3
# Database connection
conn = sqlite3.connect('./pir-files/tor-records.db')
cursor = conn.cursor()
# Execute query to get country counts again (for independence from the first plot)
cursor.execute("SELECT country, COUNT(ip) AS peer_count FROM ip_rec GROUP BY country ORDER BY peer_count DESC")
country_counts = cursor.fetchall()
# Convert to DataFrame
df = pd.DataFrame(country_counts, columns=['Country', 'Count'])
# Create the choropleth map
fig = go.Figure(go.Choropleth(
locations=df['Country'],
locationmode='country names',
z=df['Count'],
colorscale='Inferno',
colorbar_title="Number of Seeders/Uploaders"
))
# Update layout for aesthetics
fig.update_layout(
title_text="Number of Seeders/Uploaders by Country",
# title in the center
title_x=0.5,
showlegend=False,
paper_bgcolor='rgba(0,0,0,0)', # Transparent background
geo=dict(
landcolor='rgba(15,15,15,1)',
lakecolor='rgba(40,40,40,1)',
showocean=False,
bgcolor='rgba(0,0,0,0)', # Transparent geo background
framewidth=0,
showframe=False,
showcoastlines=False
),
font=dict(family="Segoe UI", color="white") # Font style and color
)
# Show the figure
fig.show()
# save the figure as an HTML file
fig.write_html('./pir-files/seeders-by-country.html', include_plotlyjs='cdn')Caveats
There are some issues related to how much are these numbers representative of seeders' spread globally.
- For each movie, I chose the torrent with the most seeders which likely leans towards English language versions. Different countries might download dubbed versions of movies using different torrents.
- Use of VPNs will hide the actual IP.
Resources
- IMDB top 250 list
- Fiddler (capture and inspects web traffic.)
- Top 20 trackers from GitHub
- GeoIp (to convert IPs to location)
- Plotly plotting library
- Raw SQLite DB file (6.95MB)