What if AI redrew the world map into new regions? Clustering ML text embeddings.
The graph is constructed using word embeddings. These embeddings are the
result of training machine learning models on text data, where they learn to
map words to numerical values that reflect their semantic relationships. In
other words, words with similar meanings have similar numerical values and
are positioned close to each other in a "vector space". For instance, the
word "croissant" and "France" are closely located in this space. The
numerical representation of a word or phrase is referred to as its word
embedding.
...and?
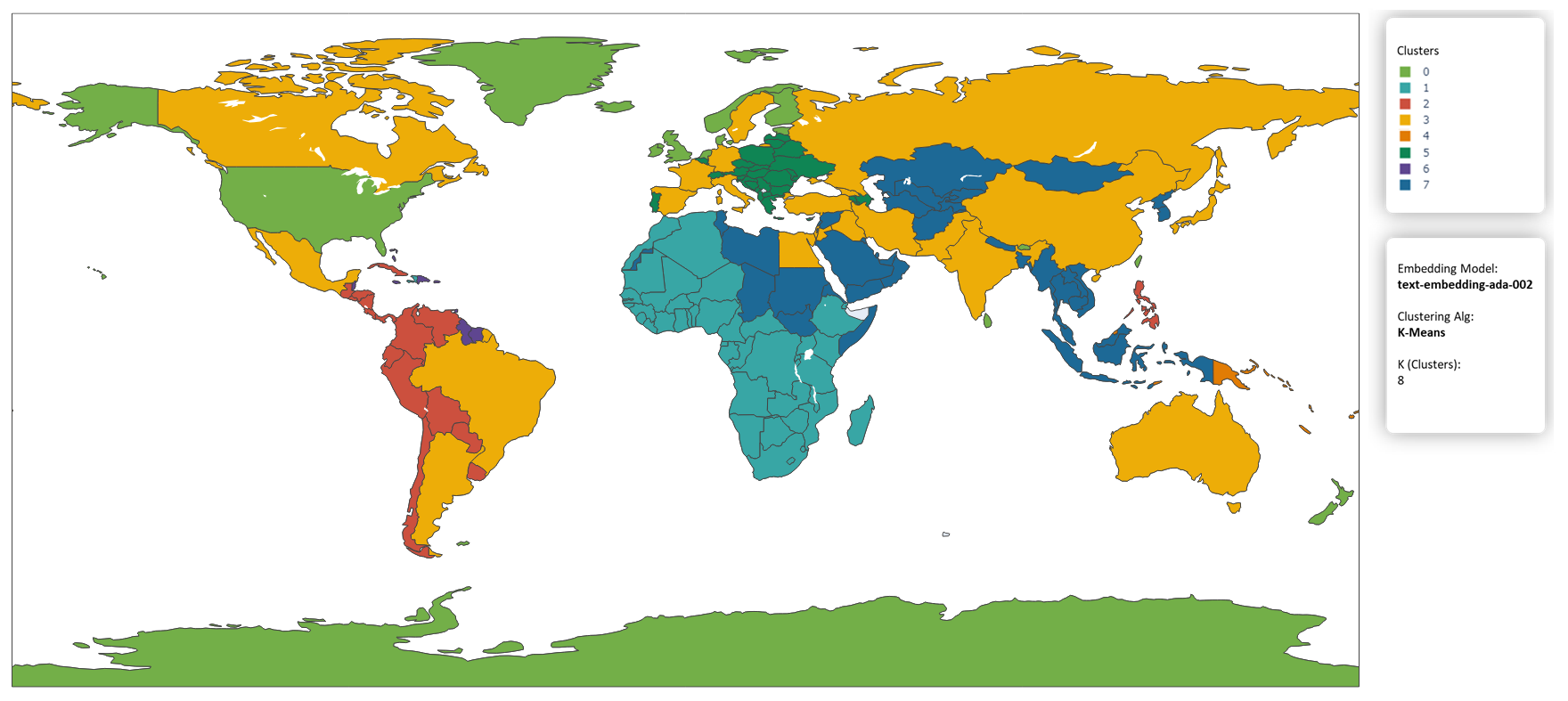
Word embeddings are a quite a helpful little tool to represent words as vectors. You can do all sorts of operations on vectors that you couldn't do on strings like calculating similarity between words or clustering them into groups. I embedded the name of each country using a machine learning model and clustered them into 7 groups and plotted the map. The color of each country in the map represents the cluster the model thinks that country should be group in.
Specifications:
Embedding model: OpenAI's text-embedding-ada-002
embedding endpoint.
Clustering Algorithm: KMeans.
Number of clusters: 8 (this is arbitrary)
How?
1. Generate embeddings for each country using a NN model.
I used OpenAI's API from their python package. You're gonna need an API key for this. Get a list of countries to iterate from. It's gonna return a list or "vector" of about 1500 values for each one.
import json
import openai
openai.api_key = open("openaiapikey.txt", "r").read()
# create a new dictionary to store the embeddings with their country names
emb_json = {}
# load country names from the json file
with open('country_names.json') as f:
countries = json.load(f)
# for each country name, create an embedding and save it in the json object
for country in countries:
embedding = openai.Embedding.create(model="text-embedding-ada-002", input=country)
emb_json[country] = embedding["data"][0]["embedding"]
print(country + " - " + str(embedding["data"][0]["embedding"]))
# save the json object as a json file
with open('country_embeddings.json', 'w') as f:
json.dump(emb_json, f)
Save it in a file with their corresponding names. You don't want to call a paid API too many times … every time. Load this later to play around with it like building word closeness map of the world. Illustrating the usual workflow:
emp_np = []
countries = []
with open('country_embeddings.json') as f:
emb_json = json.load(f)
emp_np = np.array([emb_json[country] for country in emb_json])
countries = [country for country in emb_json]2. Cluster the embeddings within groups using magic (Math).
You don't need to know how the math of this works. The folks who
wrote scikit-learn already do. It's gonna return a label for
each country corresponding to their cluster. You can cluster them into any
arbitrary number of groups. That's the K in KMeans.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=8, random_state=0).fit(emp_np)
# convert kmeans.labels_ into string labels
string_labels = [str(label) for label in kmeans.labels_]3. Make a pretty map
Use any library. I'm using Plotly.
import plotly.express as px
import pandas as pd
df = pd.DataFrame({'country': countries, 'cluster': string_labels})
fig = px.choropleth(df, locations="country", locationmode='country names',\
color="cluster", hover_name="country",\
color_discrete_sequence=px.colors.qualitative.Prism)
fig.update_traces(text=countries)
fig.show()